Важность использования технологий хранилищ данных как информационной основы для Data Mining уже рассматривалась нами. Структура хранилища, оптимизированная под задачи аналитической обработки, позволяет свести к минимуму потери времени на поиск нужных данных и получение промежуточных результатов.
Подход SAS к созданию информационно-аналитических систем
Подход компании SAS к созданию информационно-аналитических систем стандартизован в рамках SAS Intelligent Warehousing solutions, рис. 23.2.
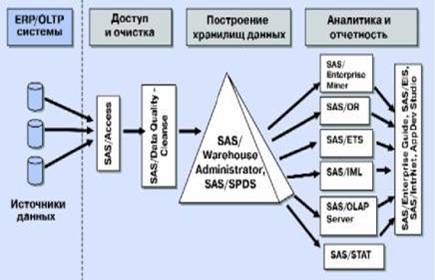
Этот подход предусматривает: • простые в использовании эффективные методы извлечения данных из ERP/OLTP-систем, баз данных и других источников без применения микропрограммирования на языке управле...
Технические требования пакета SASR Enterprise MinerПоддерживаемые клиентские платформы Microsoft Windows (32-разрядная) Windows NT 4 Workstation, Windows 2000 Professional, Windows XP Professional, AIX (64-разрядная) релиз 5.1, HPUX (64-разрядная)...
Архитектура системыПо своей природе PolyAnalyst является клиент-серверным приложением. Пользователь работает с клиентской программой PolyAnalyst Workplace. Математические модули выделены в серверную часть - PolyAnal...
PolyAnalyst Workplace - лаборатория аналитикаWorkplace - это клиентская часть программы, ее пользовательский интерфейс. Workplace представляет собой полнофункциональную среду для анализа данных, которая показана на рис. 24.2. Основные черты...
Аналитический инструментарий PolyAnalystВерсия PolyAnalyst 4.6 включает 18 математических модулей, основанных на различных алгоритмах Data и Text Mining. Большинство из этих алгоритмов являются Know-How компании Мегапьютер и не имеют ан...
Алгоритмы кластеризацииFind Dependencies (FD) - N-мерный анализ распределений Данный алгоритм обнаруживает в исходной таблице группы записей, для которых характерно наличие функциональной связи между целевой переменной...
Алгоритмы классификацииВ пакете PolyAnalyst имеется богатый инструментарий для решения задач классификации, т.е. для нахождения правил отнесения записей к одному из двух или к одному из нескольких классов. Classify (CL)...
Алгоритмы ассоциацииMarket Basket Analysis (BA) - метод анализа корзины покупателя Название этого метода происходит от задачи определения вероятности, какие товары покупаются совместно. Однако реальная область его пр...
Модули текстового анализаВ системе PolyAnalyst реализована интеграция инструментов Data Mining с методами анализа текстов на естественном языке - алгоритмов Text Mining. Иллюстрация работы модулей текстового анализа показ...
Text Analysis (ТА) - текстовый анализText Analysis представляет собой средство формализации неструктурированных текстовых полей в базах данных. При этом текстовое поле представляется как набор булевых признаков, основанных на наличии...
ВизуализацияВ PolyAnalyst имеется богатый набор инструментов для графического представления и анализа данных и результатов исследований. Данные могут представляться в различных Найденные в процессе Data Minin...
Эволюционное программированиеВ данное время эволюционное программирование является наиболее молодой и одной из многообещающих технологий Data Mining. Основная идея метода состоит в формировании гипотез о зависимости целевой п...
Общесистемные характеристики PolyAnalystТипы данных PolyAnalyst работает с разными типами данных. Это: числа, булевы переменные (yes/no), категориальные переменные, текстовые строки, даты, а также свободный английский текст. Доступ к да...
PolyAnalyst Scheduler - режим пакетной обработкиВ PolyAnalyst предусмотрена возможность пакетного режима анализа данных. Для этого имеется специальный скриптовый язык, на котором программируется все аналитические действия и временная последоват...
WebAnalystПомимо разработок PolyAnalyst и TextAnalyst, предназначенных соответственно для добычи данных и текстов (Data Mining и Text Mining), фирма Мегапьютер реализует третий продукт - WebAnalyst. WebAnal...
WebAnalyst 2Представление о комплексе программных средств компании Cognos дает следующий рис. 25.1 [108]....
WebAnalyst 3Ниже перечислены основные программные продукты Cognos, которые относятся к проблемным областям, указанным на рисунке. 1. Работа с запросами и отчетами. Решения в области работы с отчетами ориентир...
WebAnalyst 45. Защита информации. Защита информации достигается за счет использования единого для всех приложений компонента, называемого Access Manager и позволяющего описывать классы пользователей и управля...
WebAnalyst 5В основу программного продукта Cognos 4Thought положена технология нейронных сетей. Использование нейронных сетей позволяет строить достаточно точные сложные нелинейные модели на основе неполной с...
WebAnalyst 6Cognos PowerPlay - это инструментальное средство для оперативного анализа данных и формирования отчетов по OLAP-технологии. Оно позволяет аналитикам исследовать данные под любым углом зрения, обес...
WebAnalyst 74Thought поддерживает анализ на всех этапах: 1. Сбор данных. Данные вводятся непосредственно или получаются из внешних источников, например, MS Excel. Данные могут быть взяты у других программных...
Система STATISTICA Data MinerНазначение. Система STATISTICA Data Miner (разработчик - компания StatSoft [109]) спроектирована и реализована как универсальное и всестороннее средство анализа данных - от взаимодействия с различ...
Система STATISTICA Data Miner 2Рабочее пространство STATISTICA Data Miner состоит из четырех основных частей (рис. 25.5): 1. Data Acquisition -сбор данных. В данной части пользователь идентифицирует источник данных для анализа,...
Средства анализа STATISTICA Data MinerСредства анализа STATISTICA Data Miner можно разделить на пять основных классов: 1. General Slicer/Dicer and Drill-Down Explorer -разметка/разбиение и углубленный анализ. Набор процедур, позволяющ...
Средства анализа STATISTICA 2• General CHAID (Chi-square Automatic Interaction Detection) Models -обобщенные CHAID-модели (Хи-квадрат автоматическое обнаружение взаимодействия). Подобно предыдущему элементу, этот модуль являе...
Средства анализа STATISTICA 3Шаг 1. Работу в Data Miner начнем с подменю Добыча данных в меню Анализ (рис. 25.6). Выбрав пункт Добытчик данных - Мои процедуры или Добытчик данных - Все процедуры, мы запустим рабочую среду STA...
Средства анализа STATISTICA 4Шаг 2. Для примера возьмем файл Boston2.sta из папки примеров STATISTICA. В следующем примере анализируются данные о жилищном строительстве в Бостоне. Цена участка под застройку классифицируется к...
Средства анализа STATISTICA 5Шаг 3. После выбора файла появится окно диалога Выберите зависимые переменные и предикторы, показанное на рис. 25.8....
Средства анализа STATISTICA 6Выбираем зависимые переменные (непрерывные и категориальные) и предикторы (непрерывные и категориальные), исходя из знаний о структуре данных, описанной выше. Нажимаем OK. Шаг 4. Запускаем Диспетч...
Средства анализа STATISTICA 7Диспетчер узлов включает в себя все доступные процедуры для добычи данных. Всего доступно около 260 методов фильтрации и очистки данных, методов анализа. По умолчанию, процедуры помещены в папки и...
Средства анализа STATISTICA 8Источник данных в рабочей области Data Miner автоматически будет соединен с узлами выбранных анализов. Операции создания/удаления связей можно производить и вручную. Шаг 5. Теперь выполним проект....
Oracle Data MiningВ марте 1998 компания Oracle [112] объявила о совместной деятельности с 7 партнерами -поставщиками инструментов Data Mining. Далее последовало включение в Oracle8i средств поддержки алгоритмов Dat...
Oracle Data Mining -функциональные возможностиФункции - Oracle Data Mining строит прогнозирующие и дескрипторные модели. Прогнозирующие модели: • классификация; • регрессия; • поиск существенных атрибутов. Дескрипторные модели: • кластеризаци...
Краткая характеристика алгоритмов классификацииАлгоритмы Naive Bayes (NB): • Работает быстрее, чем ABN (по времени построения модели). • Этот алгоритм лучше использовать для числа атрибутов 200. • Точность алгоритма меньше, чем в ABN. Adaptive...
Алгоритмы кластеризацииАлгоритм Enhanced k-means Clustering В этом алгоритме число кластеров изначально задается пользователем. Кластеризация проводится только по числовым атрибутам, их число не должно быть слишком вели...
Поддержка процесса от разведочного анализа до отображения данныхDeductor Studio позволяет пройти все этапы анализа данных. Схема на рис. 26.2 отображает процесс извлечения знаний из данных. Рассмотрим этот процесс более детально. На начальном этапе в программу...
Поддержка процесса от разведочного анализа до отображения данных 2Поддерживаются также другие, сторонние источники: • текстовый файл с разделителями; • Microsoft Excel; • Microsoft Access; • Dbase; • CSV-файлы; • ADO-источники -позволяют получить информацию из л...
Архитектура Deductor StudioВся работа по анализу данных в Deductor Studio базируется на выполнении следующих действий: • импорт данных; • обработка данных; • визуализация; • экспорт данных. На рис. 26.3 показана схема функц...
Архитектура Deductor Studio 2• хранилище данных Deductor Warehouse ; • Microsoft Excel; • Microsoft Word; • HTML; • XML; • Dbase; • буфер обмена Windows; • текстовой файл с разделителями. Результаты каждого действия можно ото...
Архитектура Deductor Studio 3Последовательность действий, которые необходимо провести для анализа данных, называется сценарием. Сценарий можно автоматически выполнять на любых данных. Типовой сценарий изображен на рис. 26.4....
Архитектура Deductor WarehouseDeductor Warehouse - многомерное хранилище данных, аккумулирующее всю необходимую для анализа предметной области информацию. Вся информация в хранилище содержится в структурах типа звезда, где в ц...
Описание аналитических алгоритмовКроме консолидации данных, работа по созданию законченного аналитического решения содержит несколько этапов. Очистка данных. На этом этапе проводится редактирование аномалий, заполнение пропусков,...
Описание аналитических алгоритмов 2Группа 1. Очистка данных Редактирование аномалий Автоматическое редактирование аномальных значений осуществляется с применением методов робастной фильтрации, в основе которых лежит использование р...
Обнаружение дубликатов и противоречийСуть обработки состоит в том, что определяются входные и выходные поля. Алгоритм ищет во всем наборе записи, для которых одинаковым входным полям соответствуют одинаковые (дубликаты) или разные (п...
Обнаружение дубликатов и противоречий 2Группировка Трудно делать какие-либо выводы по данным каждой записи в отдельности. Аналитику для принятия решения часто необходима сводная информация. Совокупные данные намного более информативны,...
Обнаружение дубликатов и противоречий 3Алгоритмы Data Mining в пакете Deductor представлены таким набором: • нейронные сети; • линейная регрессия; • прогнозирование; • автокорреляция; • деревья решений; • самоорганизующиеся карты; • ас...
Реинжиниринг аналитического процессаИспользование в качестве инструмента для моделирования программного обеспечения KXEN предлагает усовершенствовать аналитический процесс, устранив трудности, часто возникающие в процессе поиска зак...
Технические характеристики продуктаKXEN Analytic FrameworkTM представляет собой набор описательных и предсказательных аналитических модулей, которые можно скомбинировать в зависимости от задачи заказчика. KXEN не является закрытым...
Предпосылки создания KXENВ 1990-е годы были получены важные результаты в математике и машинном обучении. Инициатором исследований в этой области стал Владимир Вапник, опубликовавший свою Статистическую Теорию Обучения. Он...
Предпосылки создания KXEN 2В результате появляются следующие требования: 1. Четкий и лаконичный API. 2. Возможность интеграции в любой пользовательский интерфейс. 3. Отсутствие необходимости временного или постоянного копир...
Структура KXEN Analytic Framework Version 3.0KXEN Analytic Framework по своей сути не является монолитным приложением, а выполняет роль компонента, который встраивается в существующую программную среду. KXEN Analytic Framework представляет с...
Структура KXEN Analytic Framework 2Рассмотрим ключевые компоненты системы KXEN. Компонент Агрегирования Событий (KXEN Event Log - KEL) предназначен для агрегирования событий, произошедших за определенные периоды времени. Применение...
Структура KXEN Analytic Framework 3Компонент Согласованного Кодирования (KXEN Consistent Coder - K2C) позволяет автоматически подготовить данные и трансформировать их в формат, подходящий для использования аналитическими приложения...
Структура KXEN Analytic Framework 4Машина Опорных Векторов KXEN (Support Vector Machine - KSVM) позволяет производить бинарную классификацию. Использование компонента подходит для решения задач, основанных на наборах данных с небол...
Технология IOLAPИ, в заключение, рассмотрим технологию IOLAPTM от KXEN - интеллектуальную оперативную аналитическую обработку, позволяющую извлечь из данных наиболее релевантную информацию. Традиционные OLAP-инст...
Data Mining-услугиПо данным консалтинговой компании Meta Group, в мире не менее 85% рынка Data Mining занимают именно услуги, т.е. консультации по эффективному внедрению этой технологии для решения актуальных бизне...
Data Mining-услуги 2Консалтинговая компания предоставляет услуги, полностью адаптированные под бизнес заказчика и его задачи. • возможность выбора наиболее удобных понятий, в терминах которых должны быть сформулирова...
Работа с клиентомНа примере российской компании SnowCactus рассмотрим процедуру работы консалтинговой компании с клиентом. Комплекс услуг этой компании включает в себя планирование, организацию и осуществление пол...
Цикл состоит из пяти этапов.Этап 1. Постановка бизнес-задачи На первом этапе компания вместе с заказчиком формулирует конкретные бизнес-задачи. При первом прохождении этого цикла задача может быть поставлена довольно широко:...
Примеры решенияВозьмем два примера решения задач, один из них - оценка кредитоспособности заемщика банка. Задача Выдавать ли кредит? уже рассматривалась нами на протяжении курса. Рассмотрим реализацию этой задач...
Техническое описание решенияКак уже отмечалось, система кредитного скоринга dm-Score является решением, полностью интегрированным с используемым в банке программным обеспечением: АБС, системой автоматизации ритейла, СУБД и д...
Техническое описание решения 2В процессе анализа данных о заемщиках и кредитах применяются различные математические методы, которые выявляют в них факторы и их комбинации, влияющие на кредитоспособность заемщиков, и силу их вл...
Техническое описание решения 3Пример 2.Анализ резюме: пример решения практической бизнес-задачи клиента. Приведем пример решения конкретной бизнес-задачи одного из рекрутинговых агентств, в которой технология Data Mining приме...
ВыводыВыбор инструментального средства Data Mining и способа его внедрения должен проводиться в соответствии с конкретными целями и задачами, учитывать уровень финансовых возможностей компании, квалифик...
