Для формулирования правил следует определить возможные значения лингвистических переменных Xi и Y, которые будут использоваться для оценки кандидатов:
d1: "Если Х1 = ПОДХОДЯЩЯЯ и X2 = ВЫСШЕЕ, и Х3 = ДОСТАТОЧНЫЙ. то Y = УДОВЛЕТВОРЯЮЩИЙ";
d2: "Если Х1 = ПОДХОДЯЩАЯ и X2 = ВЫСШЕЕ, и Х3 = ДОСТАТОЧНЫЙ, и X4 = СПОСОБЕН, то Y = БОЛЕЕ ЧЕМ УДОВЛЕТВОРЯЮЩИЙ";
d3: "Если Х1 = ПОДХОДЯЩАЯ и Х2 = ВЫСШЕЕ, и X3 = ДОСТАТОЧНЫЙ, и Х4 = СПОСОБЕН, и X5 = ОБЛАДАЕТ, то Y = БЕЗУПРЕЧНЫЙ";
d4: "Если Х1 = ПОДХОДЯЩАЯ и Х2 = ВЫСШЕЕ, и Х3 = ДОСТАТОЧНЫЙ, и X4 = ОБЛАДАЕТ, то Y = ОЧЕНЬ УДОВЛЕТВОРЯЮЩИЙ";
d5: "Если Х1 = ПОДХОДЯЩАЯ и X2 = НЕ ВЫСШЕЕ, и Х3 = ДОСТАТОЧНЫЙ, и X5 = ОБЛАДАЕТ, то Y = УДОВЛЕТВОРЯЮЩИЙ";
d6: "Если Х1 = НЕ ИМЕЕТ и Х3 = НЕДОСТАТОЧНЫЙ, то Y = НЕУДОВЛЕТВОРЯЮЩИЙ".
Переменная Y задана на множестве
J = {0; 0,1; 0,2; ...; 1}.
Значения переменной Y заданы с помощью следующих функций принадлежности:
S = УДОВЛЕТВОРЯЮЩИЙ определено как mS(х) = х, х Î J;
MS = БОЛЕЕ ЧЕМ УДОВЛЕТВОРЯЮЩИЙ — как mMS(x)=Öx; x Î J;
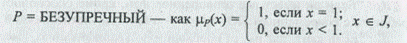
VS = ОЧЕНЬ УДОВЛЕТВОРЯЮЩИЙ — как mVS(x) = х2, x Î J,
US = НЕУДОВЛЕТВОРЯЮЩИЙ — как mVS(x) = 1 - х, х Î J.
Выбор производится из пяти кандидатов на множестве U = {u1, и2, u3, u4, u5}.
