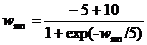 .
.
Эта функция сильно уменьшает величину очень больших весов, воздействие на малые веса значительно более слабое. Далее она поддерживает симметрию, сохраняя небольшие различия между большими весами. Экспериментально было показано, что эта функция выводит нейроны из состояния насыщения без нарушения достигнутого в сети обучения. Не было затрачено серьезных усилий для оптимизации используемой функции, другие значения констант могут оказаться лучшими.
Экспериментальное результаты.
Комбинированный алгоритм, использующий обратное распространение и обучение Коши, применялся для обучения нескольких больших сетей. Например, этим методом была успешно обучена система, распознающая рукописные китайские иероглифы [б]. Все же время обучения может оказаться большим (приблизительно 36 часов машинного времени уходило на обучение).
В другом эксперименте эта сеть обучалась на задаче ИСКЛЮЧАЮЩЕЕ ИЛИ, которая была использована в качестве теста для сравнения с другими алгоритмами. Для сходимости сети в среднем требовалось около 76 предъявлении обучающего множества. В качестве сравнения можно указать, что при использовании обратного распространения в среднем требовалось около 245 предъявлении для решения этой же задачи [5] и 4986 итераций при использовании обратного распространения второго порядка.
Ни одно из обучений не привело к локальному минимуму, о которых сообщалось в [5]. Более того, ни одно из 160 обучений не обнаружило неожиданных патологий, сеть всегда правильно обучалась.
Эксперименты же с чистой машиной Коши привели к значительно большим временам обучения. Например, при r = 0,002 для обучения сети в среднем требовалось около 2284 предъявлении обучающего множества.
