Теперь, когда найдены наиболее подходящие значения параметров распределения, рассчитаем оптимальное f для этого распределения. Мы можем применить процедуру, которая была использована в предыдущей главе для поиска оптимального f при нормальном распределении. Единственное отличие состоит в том, что вероятности для каждого стандартного значения (значения X) рассчитываются с помощью уравнений (4.06) и (4.12). При нормальном распределении мы находим столбец ассоциированных вероятностей (вероятностей, соответствующих определенному стандартному значению), используя уравнение (3.21).
В нашем случае, чтобы найти ассоциированные вероятности, следует выполнить процедуру, детально описанную ранее:
1. Для данного стандартного значения Х рассчитайте его соответствующее N'(X) с помощью уравнения (4.06).
2. Для каждого стандартного значения Х рассчитайте накопленную сумму значений N'(X), соответствующих всем предыдущим X.
3. Теперь, чтобы найти N(X), т.е. итоговую вероятность для данного X, прибавьте текущую сумму, соответствующую значению X, к текущей сумме, соответствующей предыдущему значению X. Разделите полученную величину на 2. Затем разделите полученное частное на общую сумму всех N'(X), т.е. последнее число в столбце текущих сумм. Это новое частное является ассоциированной 1-хвостой вероятностью для данного X.
Так как теперь у нас есть метод поиска ассоциированных вероятностей для стандартных значений Х при данном наборе значений параметров, мы можем найти оптимальное f. Процедура в точности совпадает с той, которая применяется для поиска оптимального f при нормальном распределении. Единственное отличие состоит в том, что мы рассчитываем столбец ассоциированных вероятностей другим способом. В нашем примере с 232 сделками значения параметров, которые получаются при самом низком значении статистики К-С, составляют 0,02, 2,76, О и 1,78 для LOC, SCALE, SKEW и KURT соответственно. Мы получили эти значения параметров, используя процедуру оптимизации, описанную в данной главе. Статистика К-С == 0,0835529 (это означает, что в своей наихудшей точке два распределения удалены на 8,35529%) при уровне значимости 7,8384%.
Рисунок 4-10 показывает функцию распределения для тех значений параметров, которые наилучшим образом подходят для наших 232 сделок. Если мы возьмем полученные параметры и найдем оптимальное f по этому распределению, ограничивая распределение +3 и -3 сигма, используя 100 равноотстоящих точек данных, то получим f= 0,206, или 1 контракт на каждые 23 783,17 доллара.
Сравните это с эмпирическим методом, который покажет, что оптимальный рост достигается при 1 контракте на каждые 7918,04 доллара на балансе счета. Этот результат мы получаем, если ограничиваем распределение 3 сигма с каждой стороны от среднего. В действительности, в эмпирическом потоке сделок у нас был проигрыш наихудшего случая 2,96 сигма и выигрыш наилучшего случая 6,94 сигма. Теперь, если мы вернемся и ограничим распределение 2,96 сигма слева от среднего и 6,94 сигма справа (и на этот раз будем использовать 300 равноотстоящих точек данных), то получим оптимальное f = 0,954, или 1 контракт на каждые 5062,71 доллара на балансе счета. Почему оно отличается от эмпирического оптимального f= 7918,04?
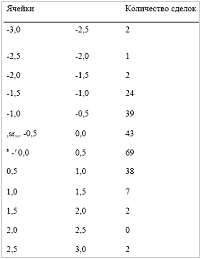
Проблема состоит в «грубости» фактического распределения. Вспомните, что уровень значимости наших наилучшим образом подходящих параметров был только 7,8384%. Давайте возьмем распределение 232 сделок и поместим в 12 ячеек от -3 до +3 сигма.