Отметьте, что на хвостах распределения находятся пробелы, т.е. области, или ячейки, где нет эмпирических данных. Эти области сглаживаются, когда мы приспосабливаем наше регулируемое распределение к данным, и именно эти сглаженные области вызывают различие между параметрическим и эмпирическим оптимальным f. Почему же наше характеристическое распределение при всех возможностях регулировки его формы не очень хорошо приближено к фактическому распределению? Причина состоит в том, что наблюдаемое распределение имеет слишком много точек перегиба. Параболу можно направить ветвями вверх или вниз. Однако вдоль всей параболы направление вогнутости или выпуклости не изменяется. В точке перегиба направление вогнутости изменяется.
Парабола имеет 0 точек перегиба,
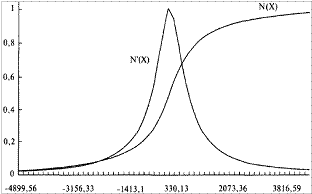
Рисунок 4-10 Регулируемое распределение для 232 сделок
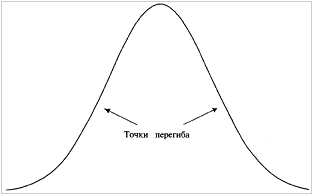
Рисунок 4-11 Точки перегиба колоколообразного распределения
так как направление вогнутости никогда не изменяется. Объект, имеющий форму буквы S, лежащий на боку, имеет одну точку перегиба, т.е. точку, где вогнутость изменяется. Рисунок 4-11 показывает нормальное распределение. Отметьте, что в колоколообразной кривой, такой как нормальное распределение, есть две точки перегиба. В зависимости от значения SCALE наше регулируемое распределение может иметь ноль точек перегиба (если SCALE очень низкое) или две точки перегиба. Причина, по которой наше регулируемое распределение не очень хорошо описывает фактическое распределение сделок, состоит в том, что реальное распределение имеет слишком много точек перегиба. Означает ли это, что полученное характеристическое распределение неверно? Скорее всего нет. При желании мы могли бы создать функцию распределения, которая имела бы больше двух точек перегиба. Такую функцию можно было бы лучше подогнать к реальному распределению. Если бы мы создали функцию распределения, которая допускает неограниченное количество точек перегиба, то мы бы точно подогнали ее к наблюдаемому распределению. Оптимальное f, полученное с помощью такой кривой, практически совпало бы с эмпирическим. Однако чем больше точек перегиба нам пришлось бы добавить к функции распределения, тем менее надежной она была бы (т.е. она хуже представляла бы будущие сделки). Мы не пытаемся в точности подогнать параметрическое IK наблюдаемому, а стараемся лишь определить, как распределяются наблюдаемые данные, чтобы можно было предсказать с большой уверенностью будущее оптимальное 1(если данные будут распределены так же, как в прошлом). В регулируемом распределении, подогнанном к реальным сделкам, удалены ложные точки перегиба.
